Modern web search engines have succeeded at solving the underlying technical problems of getting access to an ever-increasing amount of information. Nowadays, we can get search results within milliseconds thanks to web search engines. Unfortunately, this is not the end of the story.
According to a comScore study (see figure below), Internet users spend from 4-5% of their time searching and navigating the Web. That means that around 95% of the time spent on the internet we are basically sitting in front of a web page.
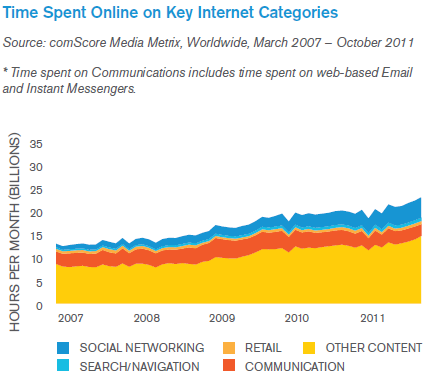
And what are we doing during this time? Well, many things. Sometimes we are having fun, working, buying things, etc. But sometimes we have to do research and we waste a lot of time searching for and reading information inside a web page because web search engines can't do that for us.
Web search engines implicitly assume that we search the web for a list of result pages with relevant links on them. But we actually search the web for information that is contained somewhere in those relevant links.
We probably spend most of our search time (not accounted for in the figure above) reading the contents of web pages and manually extracting relevant information from them. Except for the useful but insufficient search function embedded in every browser, this is a task that we have to essentially do on our own; a task that is time-consuming, cognitive-demanding, error-prone and boring.
On our next post we'll present Browseye, a tool that can help you save your time when searching for information on the web.
No comments:
Post a Comment